Tìm hiểu về AutoEncoder sử dụng pytorch
Học từ cơ bản đi lên và một cách có hệ thống thì sẽ giúp cho chúng ta có được kiến thức chắc và nhớ lâu hơn. Đây là bài viết đầu tiên trong chuỗi bài viết về Anomaly Detection, ở bài viết này mình sẽ sử dụng pytorch để thực hành về AutoEncoder.
# AutoEncoder là gì?
Trước tiên phải hiểu AutoEncoder nó là cái gì, và ứng dụng gì?
AutoEncoder là một kỹ thuật trong machine leanring, một kỹ thuật học máy không có nhãn dữ liệu. Nó có một ứng dụng phổ biến trong các bài toán về phát hiện lỗi, bất thường, chính vì vậy mà mình lấy nó làm cái gốc để đi lên trong loạt bài về Anomaly Detection.
Bài viết này sẽ sử dụng CNN(convolution neural network) đối với tập dữ liệu nổi tiếng MNIST và áp dụng AutoEncoder vào nó, tất nhiên mình code bằng pytorch, framework xu thế của tương lại.
Để hình dung cho dễ, các bạn search thêm từ khóa autoencoder bằng hình ảnh trên google để thấy được mô hình đơn giản. Hình dưới đây là mình lấy từ wikipedia.

Hiểu nôm na thì nó gồm 2 phần
- Encoder sẽ có nhiệm vụ mã hóa đầu vào thành một thông tin có chiều nhỏ hơn.
- Decoder sẽ có nhiệm vụ khôi phục lại thông tin đầu vào từ thông tin đã được mã hóa trên Và để cho thông tin đầu vào và thông tin đầu ra được giống nhau nhất(Tất nhiên khi thông tin bị giảm chiều đi tức là mất đi thì sẽ không thể khôi phục hoàn toàn, mà chỉ có thể giống nhất có thể) có thể thì 2 phần encoder và decoder đó phải học tập và điều chỉnh các thông tin bên trong chúng. Nếu đưa một đầu vào khác nhiều so với thông tin đầu vào đã được học thì sẽ không thể khôi phục được đầu vào đó, khi đó ta nói thông tin đầu vào đó là bất thường, có lỗi.
Đó là lý do vì sao nó được ứng dụng trong anomaly detection.
# Thực hành
Lý thuyết là vậy, còn thực hành thì làm sao?
Mình sẽ áp dụng autoencoder cho tập dữ liệu MNIST(gồm các chữ số viết tay từ [0-9])
# Import thư viện cần thiết
Khi thực hành bạn cần cài đặt các thư viện như python, torch, torchvision, numpy trong môi trường phát triển.
Đầu tiên là khai báo các thư viện cần thiết như sau:
import os
import numpy as np
import torch
import torchvision
from torch import nn
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.datasets import MNIST
from torchvision.utils import save_image
# Kiểm tra xem có cuda không?
cuda = torch.cuda.is_available()
if cuda:
print('cuda is available!')
# Các thông số để training
num_epochs = 100
batch_size = 128
learning_rate = 0.001
# Tạo folder xuất ra kết quả nếu chưa tồn tại
out_dir = './autoencoder'
os.makedirs(out_dir, exist_ok=True)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# Tạo data training
Tập data MNIST khi được chuyển thành tensor bằng ToTensor() thì giá trị sẽ nằm trong khoảng [0, 1]. Khi đó ta muốn chuyển nó về giá trị trong khoảng [-1, 1] thì cần áp dụng thêm transforms.Normalize().
Tạo data cho training ở đây bao gồm 2 bước
- Tạo dataset: tải trực tiếp tập dataset về thư mục
./datavà áp dụng luôn biến đổi tensor, normalize vào tập dataset đó - Sau khi có dataset thì tạo data loader để khi training thì đọc từng phần của data(gọi là
batch_size) vào training. Lúc nàyshuffle=Truethể hiện rằng sẽ xáo trộn thứ tự của data trước khi lấy ra 1 batch_size ảnh.
img_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # [0,1] => [-1,1]
])
train_dataset = MNIST('./data', download=True, transform=img_transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
2
3
4
5
6
# Xây dựng AutoEncoder
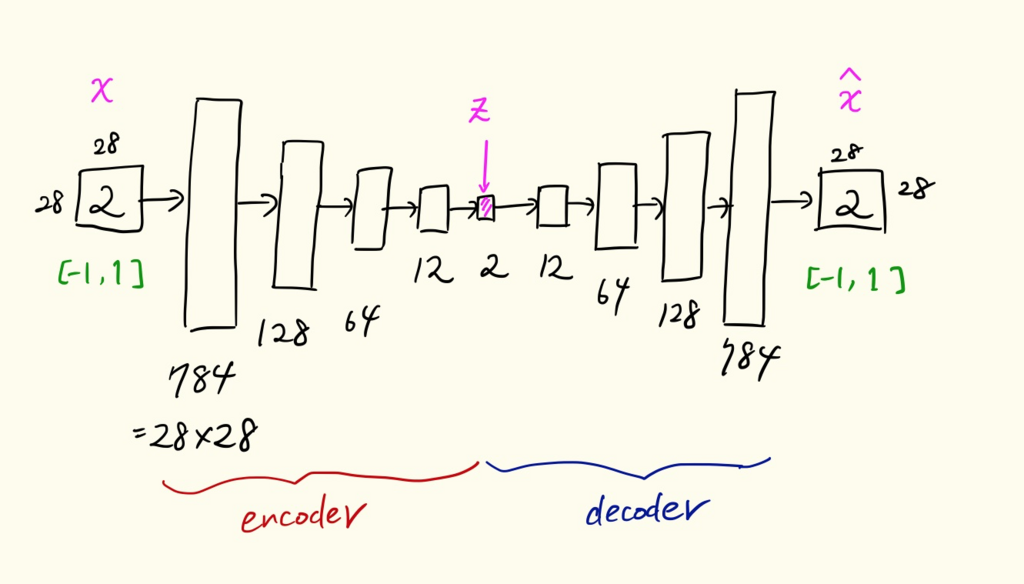
Bắt tay vào công việc chính rồi đây.
Như đã giải thích ở trên, mô hình này gồm 2 phần Encoder và Decoder. Chúng ta sẽ xây dựng một class bao gồm 2 phần này luôn.
Encoder bình thường sẽ là một multilayer neural network, với số node tại các layer giảm dần từ 784 => 128 => 64 => 12 => 2.
Giảm đến 2 tức là chúng ta sẽ biểu diễn được đầu vào (28*28) trong một Latent Space (opens new window).
Hiểu nôm na, latent space là một không gian để biểu diễn đặc trưng của data một cách trực quan. Quan sát các đặc trưng của data trong không gian này giúp ta có cái nhìn rõ hơn về data, cụ thể là bằng khoảng cách giữa các đặc trưng trong không gian này giúp ta hiểu hơn sự giống nhau và khác nhau nhiều giữa các data.
Ngược lại ở Decoder, sẽ biến đổi thông tin từ 2 => 12 => 64 => 128 => 784. Tức là biến đổi thông tin đã được nén trở về thông tin ảnh có size như ban đầu.
Bởi vì data đầu vào được chuẩn hóa về dạng [-1, 1] nên ở lớp cuối của Decoder chúng ta để thêm tanh như một hàm hoạt hóa (activation function). Lý do là vì đầu ra của tanh cũng là giá trị nằm trong khoảng [-1, 1].
Các parameter của Encoder và Decoder không share weight với nhau, và chúng được học một cách độc lập. AutoEncoder class sẽ như sau
class Autoencoder(nn.Module):
def __init__(self):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(28 * 28, 128),
nn.ReLU(True),
nn.Linear(128, 64),
nn.ReLU(True),
nn.Linear(64, 12),
nn.ReLU(True),
nn.Linear(12, 2))
self.decoder = nn.Sequential(
nn.Linear(2, 12),
nn.ReLU(True),
nn.Linear(12, 64),
nn.ReLU(True),
nn.Linear(64, 128),
nn.ReLU(True),
nn.Linear(128, 28 * 28),
nn.Tanh()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
model = Autoencoder()
if cuda:
model.cuda()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
Khi in thử model ra thì sẽ có dạng như sau
Autoencoder(
(encoder): Sequential(
(0): Linear(in_features=784, out_features=128)
(1): ReLU(inplace)
(2): Linear(in_features=128, out_features=64)
(3): ReLU(inplace)
(4): Linear(in_features=64, out_features=12)
(5): ReLU(inplace)
(6): Linear(in_features=12, out_features=2)
)
(decoder): Sequential(
(0): Linear(in_features=2, out_features=12)
(1): ReLU(inplace)
(2): Linear(in_features=12, out_features=64)
(3): ReLU(inplace)
(4): Linear(in_features=64, out_features=128)
(5): ReLU(inplace)
(6): Linear(in_features=128, out_features=784)
(7): Tanh()
)
)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# Hàm số phục hồi ảnh gốc
Như trên ta đã chuyển ảnh gốc về tensor và chuẩn hóa về [-1, 1]. Do vậy ta cần một hàm số để làm ngược lại động tác này, tức là chuyển tensor đã chuẩn hóa về ảnh gốc ban đầu. Hàm số như sau
def to_img(x):
x = 0.5 * (x + 1) # [-1,1] => [0, 1]
x = x.clamp(0, 1) # hàm này có tác dụng ép giá trị về khoảng [0, 1] nếu giá trị đó nằm ngoài biên
x = x.view(x.size(0), 1, 28, 28) # chuyển về định dạng batch_size x (ảnh 1 channel x height x weight)
return x
2
3
4
5
# Training AutoEncoder
Autoencoder là thuật toán học máy không dùng dữ liệu có nhãn. Mục tiêu để học chính là dữ liệu đầu vào luôn.
Hàm số loss ở đây là MSE (opens new window)(Mean Squared Error) chính trung bình của tổng các bình phương của sai số giữa đầu vào và đầu ra.
Việc training được thực hiện như sau
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(),
lr=learning_rate,
weight_decay=1e-5)
loss_list = []
for epoch in range(num_epochs):
for data in train_loader:
img, _ = data
x = img.view(img.size(0), -1)
if cuda:
x = Variable(x).cuda()
else:
x = Variable(x)
xhat = model(x)
# tính loss giữa đầu ra và đầu vào
loss = criterion(xhat, x)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# logging
loss_list.append(loss.data[0])
print('epoch [{}/{}], loss: {:.4f}'.format(
epoch + 1,
num_epochs,
loss.data[0]))
# cứ sau 10 epochs thì xuất ra ảnh đầu ra (ảnh đã được phục chế)
if epoch % 10 == 0:
pic = to_img(xhat.cpu().data)
save_image(pic, './{}/image_{}.png'.format(out_dir, epoch))
# save log lại dưới dạng numpy
np.save('./{}/loss_list.npy'.format(out_dir), np.array(loss_list))
torch.save(model.state_dict(), './{}/autoencoder.pth'.format(out_dir))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
# Kết quả Training
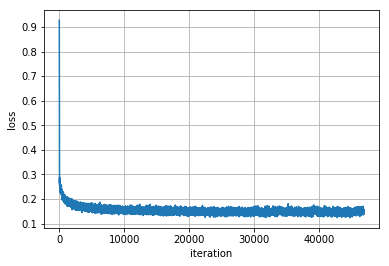
Bình thường thì sẽ vẽ lên kết quả traning cho từng epoch. Tuy nhiên bài này mình sẽ vẽ ra kết quả log của từng iteration, tức là từng mini batch.
loss_list = np.load('{}/loss_list.npy'.format(out_dir))
plt.plot(loss_list)
plt.xlabel('iteration')
plt.ylabel('loss')
plt.grid()
2
3
4
5
Kết quả plot ra như hình dưới đây
# Kiểm tra ảnh được phục chế
Có thể vào thư mục ./autoencoder để xem những ảnh đã được lưu ra trong quá trình train. Những ảnh này là những ảnh được phục chế bởi module decoder. Cứ sau mỗi 10 epochs thì lưu ra 1 ảnh.
Hoặc có thể dùng jupyter notebook để show ảnh ra như sau
from IPython.display import Image
Image('autoencoder/image_0.png')
2

from IPython.display import Image
Image('autoencoder/image_90.png')
2

# Hiển thị hóa Latent Space
Ở ví dụ này, giờ thử đi sâu hơn một chút, ta sẽ hiển thị các đặc trưng của data đầu vào sau khi qua Encoder, tức là các đặc trưng có chiều là 2 lên một không gian. Trong AI thì không gian này gọi là latent space.
Thử dùng 10k ảnh để đưa vào Encoder sau đó chiếu những vector thu được từ Encoder đó lên Latent Space để xem phân bố của nó như thế nào. Trong phần này ta chỉ dùng phần Encoder chứ không động đến phần Decoder. Chính vì cách tạo class AutoEncoder như trên nên ta có thể gọi ra Encoder một cách dễ dàng bằng cách model.encoder().
model.load_state_dict(torch.load('{}/autoencoder.pth'.format(out_dir),
map_location=lambda storage,
loc: storage))
test_dataset = MNIST('./data', download=True, train=False, transform=img_transform)
test_loader = DataLoader(test_dataset, batch_size=10000, shuffle=False)
images, labels = iter(test_loader).next()
images = images.view(10000, -1)
# vector 784 chiều thành vector 2 chiều
z = model.encoder(Variable(images, volatile=True)).data.numpy()
2
3
4
5
6
7
8
9
10
11
12
Ở đây z có shape là (10000, 2). Tiếp theo sẽ dùng matplotlib để hiển thị hóa các vector này lên cùng một không gian
import pylab
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=(10, 10))
plt.scatter(z[:, 0], z[:, 1], marker='.', c=labels.numpy(), cmap=pylab.cm.jet)
plt.colorbar()
plt.grid()
2
3
4
5
6
7
8
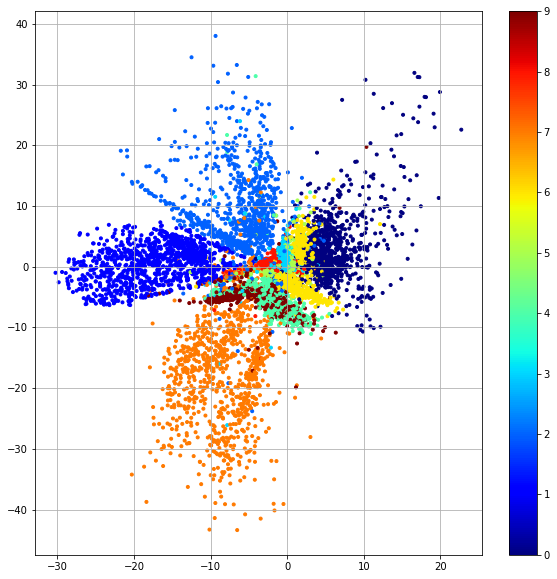
Thêm nữa, trong hình vẽ chiều X trong khoảng [-30, 20], còn Y trong khoảng [-40, 40] chính là phân bố của tập vector đặc trưng.
Ở trong bài tiếp theo chúng ta sẽ tìm hiểu thêm về VAE(Variance AutoEncoder) là một thể mở rộng của AutoEncoder. Khi đó phân bố của vector đặc trưng trong latent space sẽ có phân bố chuẩn N(0, 1).